Story 01
Summary
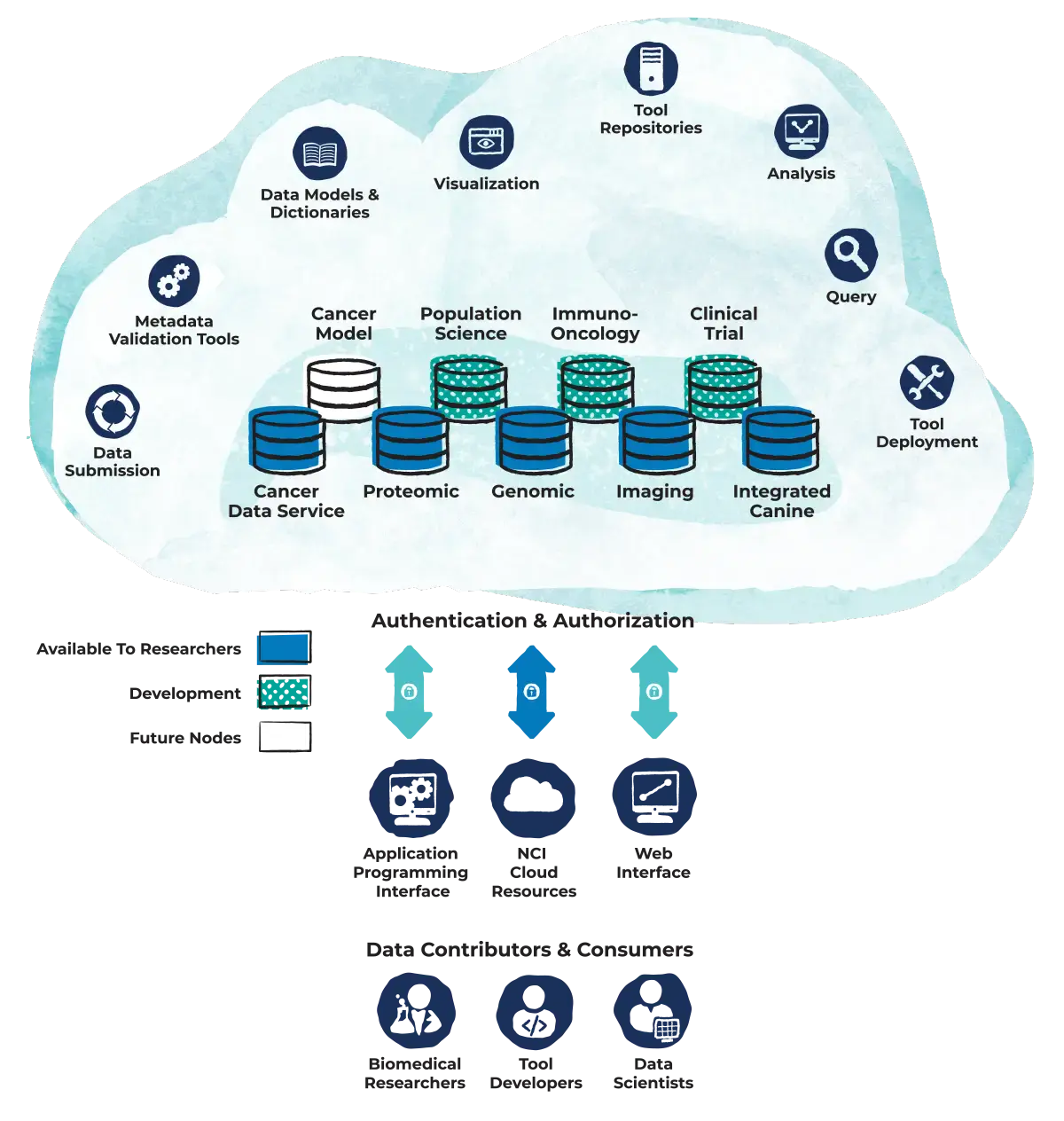
The Population Sciences Data Commons aims to serve as the centralized data repository and sharing platform for NCI-supported population studies.
Current State
Creating a national data ecosystem to equitably and responsibly collect and share cancer data will enable all cancer researchers to contribute, access, combine, and analyze diverse data related to cancer to accelerate progress against cancer.
Strategy
Build and maintain a unified cancer research data ecosystem that enables the routine collection, integration, harmonization, distribution, and reuse of data from a broad range of research studies in a secure, patient privacy-protected environment.
DCCPS Contribution
While there are multiple repositories and resources for diverse data types from studies focused on omics, imaging, and even clinical trials, there is a significant gap for hosting and broad sharing of data generated from population sciences research studies (for example, survey and questionnaire data). DCCPS is leading the way in bridging this gap by creating a new Population Sciences Data Commons, leveraging an open- and controlled-source, state-of-the-art, cloud-based platform that will be integrated into the NCI Cancer Research Cloud Data ecosystem. In partnership with colleagues across the institute, DCCPS is helping to refine the data model based on experiences with other data sources, informing the development of a data submission framework, including relevant metadata fields, and working to integrate a visualization tool. The Population Sciences Data Commons is scheduled for public release in late 2025. It will conform to the common data governing principles of NCI’s Cancer Research Data Commons and be interoperable with the other components of the ecosystem, such as the Cancer Genome Atlas, the Human Tumor Atlas Network, and the Childhood Cancer Data Initiative. In the future, this new Population Sciences Data Commons will be a tool for DCCPS-supported researchers as they develop and implement data sharing and management plans.
Story 02
Summary
The SEER Program is an invaluable research resource due to its population representativeness, linkages with several data sets, privacy protections, and data products available to verified researchers.
Current State
The electronic health record (EHR) provides data for cancer research, but it is not sufficient on its own. EHR data must be maximized and considered in the context of more comprehensive resources (such as SEER) to improve research potential.
Strategy
- Enable frictionless data sharing throughout all of cancer research and develop tools that optimize data use and analysis to achieve rapid progress.
- Support ongoing and new development of novel data visualization and analysis tools, and the infrastructure required to make them accessible to researchers.
DCCPS Contribution
Through linkages with data from key external partners, such as genomic testing companies and commercial pharmacies, the SEER Program continues to enhance the utility of SEER data for understanding cancer patients’ diagnosis, treatment, and outcomes. Since its inception in 1973, more than 23,000 publications have used SEER data, and its use has expanded exponentially in the past 10 years with the addition of new clinically relevant data. These data represent important components of a cancer patient’s trajectory over time and are essential in understanding differences in outcomes across patients with similar tumor profiles. With the expansion of the types and level of detail now available in the SEER data, new tools for data access and release were required. Therefore, the SEER Program continues to develop new tools for cohort discovery and analysis, making new data products representing important components of a cancer patient’s care freely available to researchers. One example of a linkage that provides important information about patients’ treatment and prognosis is a data set that includes cases diagnosed in California and Georgia linked to genetic testing results. Although the SEER data are de-identified, the expanding detail and longitudinal capture of information has necessitated new processes for accessing the data. Therefore, the SEER Program has developed a robust authentication and authorization process with varying requirements for researchers to obtain access to specific data sets, depending on the sensitivity of the data.
In addition to the many data products through which researchers can access the enhanced SEER data, the program has developed other innovative tools that are useful to researchers, patients, and providers. Examples include the Explorer tools and the National Childhood Cancer Registry (NCCR) Data Platform. Both resources represent new and efficient ways by which SEER and NCCR data can be accessed. The program continuously generates new processes and data access methods to meet the evolving SEER Program and to support broad access by researchers to these data.

Continue To